Long short term memory
Long short term memory or LSTM is a recurrent neural network (RNN) architecture (an artificial neural network) published[1] in 1997 by Sepp Hochreiter and Jürgen Schmidhuber. Like most RNNs, an LSTM network is universal in the sense that given enough network units it can compute anything a conventional computer can compute, provided it has the proper weight matrix, which may be viewed as its program. (Of course, finding such a weight matrix is more challenging with some problems than with others.) Unlike traditional RNNs, an LSTM network is well-suited to learn from experience to classify and process and predict time series when there are very long time lags of unknown size between important events. This is one of the main reasons why LSTM outperforms alternative RNNs and Hidden Markov Models and other sequence learning methods in numerous applications. For example, LSTM achieved the best known results in unsegmented connected handwriting recognition[2], and in 2009 won the ICDAR handwriting competition.
Contents |
Architecture
An LSTM network is an artificial neural network that contains LSTM blocks instead of, or in addition to, regular network units. An LSTM block may be described as a "smart" network unit that can remember a value for an arbitrary length of time. An LSTM block contains gates that determine when the input is significant enough to remember, when it should continue to remember or forget the value, and when it should output the value.
A typical implementation of an LSTM block is shown to the right. The four units shown at the bottom of the figure are sigmoid units. (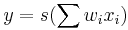 , where s is some squashing function, such as the logistic function.) The left-most of these units computes a value which is conditionally fed as an input value to the block's memory. The other three units serve as gates to determine when values are allowed to flow into or out of the block's memory. The second unit from the left (on the bottom row) is the "input gate". When it outputs a value close to zero, it zeros out the value from the left-most unit, effectively blocking that value from entering into the next layer. The second unit from the right is the "forget gate". When it outputs a value close to zero, the block will effectively forget whatever value it was remembering. The right-most unit (on the bottom row) is the "output gate". It determines when the unit should output the value in its memory. The units containing the
, where s is some squashing function, such as the logistic function.) The left-most of these units computes a value which is conditionally fed as an input value to the block's memory. The other three units serve as gates to determine when values are allowed to flow into or out of the block's memory. The second unit from the left (on the bottom row) is the "input gate". When it outputs a value close to zero, it zeros out the value from the left-most unit, effectively blocking that value from entering into the next layer. The second unit from the right is the "forget gate". When it outputs a value close to zero, the block will effectively forget whatever value it was remembering. The right-most unit (on the bottom row) is the "output gate". It determines when the unit should output the value in its memory. The units containing the 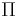 symbol compute the product of their inputs (
symbol compute the product of their inputs (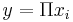 ). These units have no weights. The unit with the
). These units have no weights. The unit with the 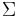 symbol computes a linear function of its inputs (
symbol computes a linear function of its inputs (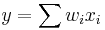 .) The output of this unit is not squashed so that it can remember the same value for many time-steps without the value decaying. This value is fed back in so that the block can "remember" it (as long as the forget gate allows). Typically, this value is also fed into the 3 gating units to help them make gating decisions.
.) The output of this unit is not squashed so that it can remember the same value for many time-steps without the value decaying. This value is fed back in so that the block can "remember" it (as long as the forget gate allows). Typically, this value is also fed into the 3 gating units to help them make gating decisions.
Training
To minimize LSTM's total error on a set of training sequences, iterative gradient descent such as backpropagation through time can be used to change each weight in proportion to its derivative with respect to the error. A major problem with gradient descent for standard RNNs is that error gradients vanish exponentially quickly with the size of the time lag between important events, as first realized in 1991[3][4]. With LSTM blocks, however, when error values are back-propagated from the output, the error becomes trapped in the memory portion of the block. This is referred to as an "error carousel", which continuously feeds error back to each of the gates until they become trained to cut off the value. Thus, regular backpropagation is effective at training an LSTM block to remember values for very long durations.
LSTM can also be trained by a combination of artificial evolution for weights to the hidden units, and pseudo-inverse or support vector machines for weights to the output units[5]. In reinforcement learning applications LSTM can be trained by policy gradient methods or evolution strategies or genetic algorithms.
Applications
Applications of LSTM include:
- Robot control[6]
- Time series prediction[7]
- Speech recognition[8][9]
- Rhythm learning[10]
- Music composition[11]
- Grammar learning[12][13][14]
- Handwriting recognition[15][16]
See also
- Artificial neural network
- Prefrontal Cortex Basal Ganglia Working Memory (PBWM)
- Recurrent neural network
- Time series
References
- ^ S. Hochreiter and J. Schmidhuber. Long short-term memory. Neural Computation, 9(8):1735–1780, 1997.
- ^ A. Graves, M. Liwicki, S. Fernandez, R. Bertolami, H. Bunke, J. Schmidhuber. A Novel Connectionist System for Improved Unconstrained Handwriting Recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 31, no. 5, 2009.
- ^ S. Hochreiter. Untersuchungen zu dynamischen neuronalen Netzen. Diploma thesis, Institut f. Informatik, Technische Univ. Munich, 1991.
- ^ S. Hochreiter, Y. Bengio, P. Frasconi, and J. Schmidhuber. Gradient flow in recurrent nets: the difficulty of learning long-term dependencies. In S. C. Kremer and J. F. Kolen, editors, A Field Guide to Dynamical Recurrent Neural Networks. IEEE Press, 2001.
- ^ J. Schmidhuber, D. Wierstra, M. Gagliolo, F. Gomez. Training Recurrent Networks by Evolino. Neural Computation, 19(3): 757-779, 2007.
- ^ H. Mayer, F. Gomez, D. Wierstra, I. Nagy, A. Knoll, and J. Schmidhuber. A System for Robotic Heart Surgery that Learns to Tie Knots Using Recurrent Neural Networks. Advanced Robotics, 22/13-14, p. 1521-1537, 2008.
- ^ J. Schmidhuber and D. Wierstra and F. J. Gomez. Evolino: Hybrid Neuroevolution / Optimal Linear Search for Sequence Learning. Proceedings of the 19th International Joint Conference on Artificial Intelligence (IJCAI), Edinburgh, p. 853-858, 2005.
- ^ A. Graves and J. Schmidhuber. Framewise phoneme classification with bidirectional LSTM and other neural network architectures. Neural Networks 18:5-6, pp. 602-610, 2005.
- ^ S. Fernandez, A. Graves, J. Schmidhuber. An application of recurrent neural networks to discriminative keyword spotting. Intl. Conf. on Artificial Neural Networks ICANN'07, 2007.
- ^ F. Gers, N. Schraudolph, J. Schmidhuber. Learning precise timing with LSTM recurrent networks. Journal of Machine Learning Research 3:115-143, 2002.
- ^ D. Eck and J. Schmidhuber. Learning The Long-Term Structure of the Blues. In J. Dorronsoro, ed., Proceedings of Int. Conf. on Artificial Neural Networks ICANN'02, Madrid, pages 284-289, Springer, Berlin, 2002.
- ^ J. Schmidhuber, F. Gers, D. Eck. J. Schmidhuber, F. Gers, D. Eck. Learning nonregular languages: A comparison of simple recurrent networks and LSTM. Neural Computation 14(9):2039-2041, 2002.
- ^ F. A. Gers and J. Schmidhuber. LSTM Recurrent Networks Learn Simple Context Free and Context Sensitive Languages. IEEE Transactions on Neural Networks 12(6):1333-1340, 2001.
- ^ J. A. Perez-Ortiz, F. A. Gers, D. Eck, J. Schmidhuber. Kalman filters improve LSTM network performance in problems unsolvable by traditional recurrent nets. Neural Networks 16(2):241-250, 2003.
- ^ A. Graves, J. Schmidhuber. Offline Handwriting Recognition with Multidimensional Recurrent Neural Networks. Advances in Neural Information Processing Systems 22, NIPS'22, p 545-552, Vancouver, MIT Press, 2009.
- ^ A. Graves, S. Fernandez,M. Liwicki, H. Bunke, J. Schmidhuber. Unconstrained online handwriting recognition with recurrent neural networks. Advances in Neural Information Processing Systems 21, NIPS'21, p 577-584, 2008, MIT Press, Cambridge, MA, 2008.
External links
- Recurrent Neural Networks with over 30 LSTM papers by Jürgen Schmidhuber's group at IDSIA